
Regular Issue, Vol. 11 N. 2 (2022), 129-146
eISSN: 2255-2863
DOI: https://doi.org/10.14201/adcaij.26764
|
ADCAIJ: Advances in Distributed Computing and Artificial Intelligence Journal
Regular Issue, Vol. 11 N. 2 (2022), 129-146 eISSN: 2255-2863 DOI: https://doi.org/10.14201/adcaij.26764 |
An Ensemble Classification and Regression Neural Network for Evaluating Role-based Tasks Associated with Organizational Unit
Ahmed Alrashedia and Maysam Abbodb
a College of Business, Human Resources Department, University of Jeddah, Saudi Arabia
b Department of Electronic and Computer Engineering, Brunel University London
aalrashedi2010@gmail.com, Maysam.Abbod@brunel.ac.uk
ABSTRACT
In this paper, we have looked at how easy it is for users in an organisation to be given different roles, as well as how important it is to make sure that the tasks are done well using predictive analytical tools. As a result, ensemble of classification and regression tree link Neural Network was adopted for evaluating the effectiveness of role-based tasks associated with organization unit. A Human Resource Manangement System was design and developed to obtain comprehensive information about their employees’ performance levels, as well as to ascertain their capabilities, skills, and the tasks they perform and how they perform them. Datasets were drawn from evaluation of the system and used for machine learning evaluation. Linear regression models, decision trees, and Genetic Algorithm have proven to be good at prediction in all cases. In this way, the research findings highlight the need of ensuring that users tasks are done in a timely way, as well as enhancing an organization’s ability to assign individual duties.
KEYWORDS
neural network; genetic algorithm; decision trees; non-linear model
1. Introduction
The administration of an organization’s human resources, such as recruitment, employment, deployment, and retention of workers, is known as human resource management (HRM) (Boxall, 2013). It is frequently referred to as «the act of considering humans as resources and assets». This typically covers all the management duties and policies toward dealing with individuals in an organization. It also concerns the working relationships of an organization as well as the policies and tasks associated with individual effort (Lim et al., 2017). There’s no denying that employees are a valuable asset to any organisation, and the goal is to make efficient use of them in order to reduce risk and maximise return on investment. To do so, it’s critical to keep accurate records and to use a straightforward management system appropriate for the situation in question (Saiz-Rubio and Rovira-Más, 2020). There are numerous considerations to be taken into account when developing an automated system for managing people at work in order to achieve the organization’s mission objectives (Sony and Naik, 2020). In fact, it is necessary to develop a comprehensive set of parameters that encompasses all aspects of organizational strengthening in order to achieve success (Margherita et al., 2021). These should include everything from the people’s culture to their working conditions and responsibilities. In order to achieve the company’s objectives, a human resource system could be assumed by an automated-aided system that will handle that task. This system will be able to use automated utilization of resources to effectively hire employees with the necessary skills and assist with training and development of current employees (Wheeler and Buckley, 2021).
In light of the large number of human resource management systems currently available and the widespread adoption of these systems by many organizations, the majority of studies concentrate on the design and development of new human resource management systems to deal with an increase in organizational commitment. Artificial intelligence applications in human resource management have also been shown to have a wide range and impact in prior studies (Qamar et al., 2021) In the future, artificial intelligence (AI) in HR management is projected to have a positive impact on performance evaluation and other organisational processes. The work of Jin and Wang (2020), who use the multi-mode fuzzy logic control algorithm to evaluate the comprehensive level of employees’ competence by establishing the degree of membership of work ability, has highlighted many aspects of the operations of these systems. This work is critical to these because it demonstrates the effectiveness of the multi-mode fuzzy logic control algorithm. Motivated by the study of Laudon and Laudon (2015) in articulating a general consensus about specialized functional assignments that the HRMS deals with, there is a need to evaluate how it is used and invested to facilitate human resource management in an administrative capacity. The research also revealed that a system dedicated to managing human resources needs to be connected to functional information subsystems, especially at the strategic level. On the other hand, Maier et al. (2013) reveals that with HRMS, managers get time to conduct essential strategic tasks by shortening wait times for responsibilities such as data entry. Although it is also indicated that when these users are unhappy with the system, it is possible that it will fail because they will not provide the information that is needed when it is needed (Melville et al., 2010). This articulating that coordination of the actions of the various elements is a critical task in HRMS (Schultze and Leidner, 2002).
It was long before computers were introduced that control information systems were implemented. According to Jääskeläinen et al. (2020), it first appeared in the field of account administration and other administrative areas. Considering the dynamic and progressive organizations have digital desires and are interested in using HRMS. Many organizations show how businesses should leverage their implementation of HRMS in order to better meet operational requirements while also considering the longer-term effect on business operations by increasing the amount of technical and digital activity delivered (Jawabreh et al., 2020). That is why this study designed and developed HRMS in order to understand and interpret the outcomes of its activities. The output or performance measurements must be evaluated and also to discover their capabilities, skills, and task assignments and how they carry them out. Hence, a machine learning algorithm was proposed and applied. This is justified by the fact that nowadays; human resource management software includes more than just undertaking a single task. It also includes recruiting and record-keeping, training, and performance appraisal, all of which have helped to shift HRM from a task-oriented to a people-oriented perspective (Bilgic, 2020).
1.1. Overview of the Development of HRSM
The results of this study have resulted in the development of a programme for human resource management (HRM) that evaluates employee performance. In order to accomplish this, the programme intends to take advantage of the most up-to-date technologies and artificial intelligence. Employee information, work performed and how it was performed, previous and current evaluations from previous and current supervisors, available training programmes, and employee complaints can all be obtained from the website by the manager. This is intended to be as accurate as possible, similar to the study performed in Ullah et al. (2021). When combined, this information provides a clear and accurate picture of the employee, as well as guidance on how to develop and benefit from them to the greatest extent possible. Managers can quickly and easily navigate between website pages in order to gather information in a more organised fashion. Once the programme has been run through once, the manager will have a comprehensive understanding of their employee’s history, from the time of his or her hire to the present day and everything in between. Thus, the Internet’s progress has a substantial impact on the employment of AI in human resources. As a result of the widespread usage of AI for HR management in the public sector, synchronous implementation might be widely deployed (Abdeldayem and Aldulaimi, 2020). AI in HR management has the ability to develop into hitherto unimagined schemes, as this claim suggests. Causation, randomness, and process formalisation have all been found to be economically efficient and socially acceptable for AI-supported practises in human resources management (Tambe et al., 2019). Artificial intelligence and human resource functions have a positive association, based on an examination of the linkage, between innovativeness and the ease with which artificial intelligence can be applied in human resource management operations. As a result, one of the factors for determining the AI tool’s effectiveness and efficiency is based on the AI tool’s concept and user friendliness (Bhardwaj et al., 2020). Artificial intelligence has also been shown to be cost-effective and time-saving in HR operations. Managing tasks, coordination, and control now takes a fraction of the time it used to. As a result, in this instance, time is of the essence. Artificial intelligence must be trusted as a decision-making tool by businesses (Kolbjrnsrud et al., 2016).
Through the use of this programme, Human Resources Management will benefit from information technology, which will allow it to record information, save information, and retrieve information in an accurate, timely, and secure manner, and increase its ability to communicate, either with its employees or with other Society companies, as well as assist it in the process of making the best decision possible It is also anticipated that the artificial intelligence that has been used in this programme will be beneficial, because artificial intelligence has the ability to simulate human intelligence by machines, and it uses the available databases to connect and analyse it, then infer correct solutions with accuracy and speed that exceeds human capacity.
This programme will enable the Human Resources Department to obtain comprehensive information about their employees’ performance levels, as well as determine their capabilities, skills, and tasks that they perform and how they accomplish them, through the use of technology. The system has provision for providing individual to record a voluntary task (see Figure 1).
Figure 1. The provision to Record Voluntary Tasks
In addition, the administration will be fully aware of their previous experiences, the level of their attendance, the training that they have received and how it has affected their performance, as well as the complaints that have been lodged against them and the validity of those complaints. Obtaining this information would allow the human resources department to develop a comprehensive picture of the employee’s performance levels and to implement appropriate training programmes to enhance the employee’s distinguishing characteristics while also addressing the employee’s weaknesses. HRM would be able to place each employee in the appropriate position as a result, allowing the company to reap the maximum benefit from each and every employee.
Additionally, this programme is regarded as a tool to help the employee understand his or her responsibilities and duties, which will serve as the basis for his or her evaluation. He would be able to perform his duties effectively if he was familiar with the work procedures. It would also examine its previous and current evaluations in order to determine its realistic level from the administration’s perspective, with the option of objecting to and discussing the results of the evaluations in question. He would be more satisfied with the organizational decisions if he could resolve this issue. Aside from that, the employee would be able to recommend specific training programmes that would assist them in increasing their efficiency and productivity. It should be clear from the foregoing that this programme has numerous benefits that accrue to HRM, direct managers, senior managers, and employees as a whole, and that these benefits are returned to the organisation in the form of benefits that enable it to achieve its goals with less time, less effort, less cost, and higher production.
1.2. Overview of Ensemble Classification and Regression Neural Network
A combination of predictive analytics and Neural Networks was used in this study (NN) and that is why is describe as an Ensemble. Instead of using predictors to obtain insights into data and its structure, neural networks (NN) strive to efficiently reflect the underlying qualities of the data in terms of accuracy and development over time, in addition to delivering good predictions outcomes (Karlaftis and Vlahogianni, 2011). Given the fact that predictive analytics can also explain phenomena under investigation through interpretations, NN applications do not target interpretation but rather marginal effects and signs that are more flexible than other predictive analytics because a functional form can be approached through learning rather than being assumed a priori, as is the case with some predictive analytics.
To improve prediction, ensembles integrate numerous claims or apply multiple learning methods, where the best of them can be produced utilising the best of any of the component learning algorithms (Usman et al., 2020). Unlike traditional models, alternative models are available in machine learning groups in a limited number, but they often provide a considerably more flexible structure for such models (Gong et al., 2020). Ensemble predictions are typically more computationally intensive than single model predictions, and this is true in the majority of circumstances. In some ways, ensemble learning can be viewed as a means to compensate for inefficient learning algorithms by performing a significant amount of additional computing (Duan, et al., 2007). On the other hand, the alternative is to get a great deal more knowledge about a single non-ensemble system. An ensemble system can be more efficient in terms of total accuracy improvement by spreading the same increase in computing, storage, or communication resources among two or more methods, rather than increasing the resource usage for a single method (Folino et al., 2021).
In this study, bagging is the type of Ensemble method used; but other Ensemble techniques such as boosting and stacking of the ensemble methods can be used (Dou et al., 2020). These techniques are now widely implemented and have been extensively investigated in several areas of studies. Bagging dwells on aggregating various machine learning techniques usually on classification and regression technique (Breiman, 1996; Bühlmann, 2012; Yariyan, et al., 2020). It means placing equal weight in the ensemble bag on each model. Bagging is possible to train ensemble models by using a randomly selected subset of the training sets, which increases the variance of the ensemble models. In addition, new versions of bagging that include online bagging are currently adopted (Seni and Elder, 2010). Neural bagging network for the prediction of Urban traffic flow has been proposed in Moretti et al. (2015). Furthermore, this study combining four different approach that includes neural networks to forecast regression across the entire hierarchical ensemble predictors for the purpose of classification and regression neural network of evaluating role-based tasks associated with the organizational unit. The machine learning classification and regression predictor were used to determine which phase the individual tasks should be structured in order to produce more accurate results, and which phase the organisational individual tasks should not be structured.
2. Methodology
This study extends from the design and development of HRMS in Ahmed et al. (2021) and conceptualized linear regression models, decision trees, and a Genetic Algorithm in order to simulate the performance of the role-based tasks associated with organizational unit. This is similar to the approach of Vu et al. (2020) who proposed an agent-based simulation modelling software architecture for building social mechanisms. It is also toward Trejos, et al. (2016) implementation technique where the use of a genetic algorithm was applied minimize the least squares criterion when dealing with multiple linear regression’s problem of variable selection. Hence, the current study will build a model in order to select the best one, by determine the validity of each attributes.
A number of considerations were taken into account when choosing these four algorithms, the first of which being the availability of computer resources. Artificial Neural Networks are more complex in terms of computation than traditional algorithms due to the additional complexity and time necessary for Decision Tree training, while Genetic Algorithm provides higher computational capability for linear regression. When compared to other machine learning techniques, Linear Regression has much less processing capacity.
The «data» that is currently available is another rationale for using the four algorithms. In order to use Artificial Neural Networks in their applications, data must be normalised and scaled. Missing values in the data gathering might also lead to low accuracy. The employment of genetic algorithms, on the other hand, necessitates the normalisation and scaling of data. Missing values in the data gathering might also lead to low accuracy. When using a Decision Tree to analyse a situational analysis problem, no data normalisation or scaling is required. Another thing to keep in mind is that missing values in the data have no bearing on the decision tree development process. Linear regression is a statistical approach for determining the nature of the connection between variables in linearly separable datasets. It’s usually utilised to figure out what kind of relationship exists between variables.
In addition to the first two justifications for using these four algorithms, the final justification is based on algorithm operations, where Artificial Neural Networks (ANNs) operations are inspired by biological processes, providing yet another justification for using the four algorithms in this study. It was created to imitate how a human brain analyses and processes information, to be more exact. The usage of genetic algorithms, on the other hand, is employed to address both limited and unconstrained optimization issues. Genetic algorithms function by using a natural selection process to simulate the process of biological evolution. The Decision Tree is a data mining method that is often used for, among other things, developing classification systems based on many covariates or developing prediction algorithms for a target variable. If you want to model the relationship between two variables, you can use linear regression. It works by fitting the data you’ve gathered into a linear equation. When two variables are compared, one is called an explanatory variable and the other is called a dependent variable, with the explanatory variable being the more important of the two.
2.1. Linear Regression
The ability to highlight the important or contribution of a variable among combination of variables dwells on the nature of the dataset under investigation. Regression analysis is one of the most important analysis that can determining y prediction how important or the level of contribution a variable can make (Spooner, et al., 2020) The ordinary least squares estimator is important in linear regression, and it may sometimes seem like there are no other estimators that are reasonable and applicable. While there are other options, most of them are good for specific scenarios (Montgomery, et al., 2021). Linear regression is a type of predictive analysis that is both simple and widely used (LR). In the context of the overall concept of regression, two aspects are discussed: (1) Does a collection of predictor variables do a good job of predicting an outcome variable? (2) Does a collection of predictor variables predict an outcome variable? Second, which variables are significant predictors of the outcome variable and in what ways do they influence the outcome variable are discussed. Rationally projected relationships between one dependent variable and one or more independent variables can be used to explain the relationship between two or more independent variables.
The naming of variables. There are several terms that can be used to describe the dependent variable in a regression. It is possible to name an outcome variable, a criteria variable, an endogenous variable, or a regression. There are several names for independent variables in regression analysis, including exogenous variables, predictor variables, and repressors. Determining the strength of predictors, predicting an outcome, and trend forecasting are three of the most common applications for regression analysis.
2.2. Genetic Algorithm
In computer science, a genetic algorithm (GA) is a search-based optimization methodology that is based on the principles of Genetics and Natural Selection. Also, it is employed in the search for ideal or near-optimal solutions to difficult problems that would otherwise take a lifetime to resolve by other means. It is also employed in the optimization of problems, as well as in science and machine learning applications. Throughout the history of mankind, nature has served as a great source of inspiration. GAs are search-based algorithms that are based on the concepts of natural selection and genetics, respectively. GA is a subset of a much broader computing branch known as Evolutionary Computation, which is a subset of GA. In computer science, there are a wide range of issues to consider, including NP-Hardness. What this essentially means is that even the most efficient computer systems take an extremely long time (sometimes years!) to solve the problem. GAs proved to be an effective tool in this situation, delivering functional near-optimal solutions in a relatively short period of time. It is possible that there is a pool or a population of potential alternatives to the problem under consideration in GAs. Recombination and mutation of these solutions result in the creation of new offspring. The process is repeated over successive generations of children. Each individual has a fitness value assigned to them, and the fitter individuals have a greater chance of mating and producing more fit individuals than the less fit individuals. Despite the fact that genetic algorithms are sufficiently randomized in nature, they perform significantly better than random local search because historical knowledge is frequently utilized.
2.3. Decision Trees
A decision tree is a useful algorithm for machine learning tasks that can be used for both regression and classification tasks. A decision tree is so named because the algorithm breaks down a large dataset into smaller and smaller pieces until the data is broken down into single instances that are then categorized, thus earning the term «decision tree». Imagine a tree with several leaves, which would represent the way the groups are divided if you were to imagine the algorithm’s results. A decision tree has a lot in common with a flowchart. When using a flowchart, you begin at the beginning point, or root, of the chart and then move on to one of the next possible nodes based on how you respond to the filtering criteria of the starting node. If the process reaches a conclusion, it is repeated. Every internal node in a decision tree is subjected to some form of testing or filtering criteria, and all decision trees function in the same way. Those on the outside, known as «leaves», are the nodes that connect the tree’s endpoints to the data point in question and serve as labels for that data point. The branches that lead from the internal nodes to the next node are made up of features or combinations of characteristics. Those paths that lead from the root to the leaves serve as the rules by which the data points are defined.
2.4. Neural Networks
Neural networks are mathematical models that store knowledge by utilising learning algorithms that are inspired by the human brain. Given that neural networks are used in computers, they are collectively referred to as a ’artificial neural network,’ which stands for artificial neural network. Machine learning is a term that is frequently heard in this field these days, and it refers to the scientific discipline that is concerned with the design and development of algorithms that allow computers, such as sensor data or databases, to learn on the basis of data. In machine-learning research, one of the primary goals is for computers to learn to recognise complex patterns automatically and to make intelligent data-based decisions based on that information. Aside from statistics and data processing, machine learning is also closely associated with fields such as pattern recognition, artificial intelligence, and pattern recognition. Despite the fact that neural networks are a popular machine learning platform, there are numerous other machine learning techniques, such as logistic regression and support for vector machines.
Deep learning algorithms are currently being used, and they provide better accuracy than standard neural networks. However, while they may appear to be black boxes on the surface, they are actually striving to do the same thing as every other model on the inside in order to make accurate predictions.
2.5. The Reason for Adopting the Four Types of the Algorithms
The fact that «an increasing number of scientific methods are turning to predictive analytics and machine learning to support and construct predictive models that will speed up discovery» (Gupta et al., 2021) is one of the reasons why this study used four different types of algorithms. In a similar vein, predictive analytics «incorporates and conducts prediction with the highest likelihood of success and the lowest amount of mistake feasible» (Zhang et al., 2020) Furthermore, the purpose of research incorporating predictive models into human resource management is to increase the dependability as well as the speed with which decisions are made. It was for this reason that predictive analytical tools, such as data modelling and machine learning, were employed in this work. Precision analytics has the ability to be applied to any unknown event in order to produce predictions about what will happen next. As shown in Table 1, a comparison of the four algorithms used to determine their performance is presented, which includes a discussion of the merits and disadvantages of each technique, as well as the rationale for selecting them to be used in the development of the performance appraisal system.
Table 1. Research Data Collection Instruments
Artificial Neural Network (ANN) |
Genetic Algorithm (GA) |
Decision Tree (DT) |
Linear Regression (LR) |
ANNs are more complex in computing terms than traditional algorithms. |
A GA has a higher computational power than linear regression. |
DT training is relatively expensive as it is more complex and takes more time. |
LR has considerably lower computational power when compared to some of the other machine learning algorithms |
ANNs require normalization and scaling of data. Also, missing values in the data cause low accuracy. |
GAs require normalization and scaling of data. Also, missing values in the data cause low accuracy. |
A DT does not require normalization or scaling of data. Missing values in the data also do NOT affect the process of building a DT to any considerable extent. |
LR fits linearly separable datasets almost perfectly and is often used to find the nature of the relationship between variables. |
ANNs are biologically inspired computational networks. ANN are designed to simulate the way the human brain analyses and processes information. |
GAs solve both constrained and unconstrained optimization problems based on a natural selection process that mimics biological evolution. |
A DT is a commonly used data mining method for establishing classification systems based on multiple covariates or for developing prediction algorithms for a target variable. |
LR attempts to model the relationship between two variables by fitting a linear equation to observed data. One variable is considered to be an explanatory variable, and the other is considered to be a dependent variable. |
2.6. Datasets
The datasets for this study are generated from the evaluation instrument build for the research (see Table 2). These instruments comprise of Performance appraisal which is one of the core dimensions in this study, with 11 items, followed by «Performance and Software Benefit» with 6 items, «Performance Aims/Objectives» with 5 items, «Job Description» with 13 items, «Clarity» with 8 items, «Importance» with 5 items, «Utilization of Artificial Intelligence» with 11 items, and «Technology Adoption Factors» with 8 items.
Table 2. Research Data Collection Instruments
Var no. |
Name |
min |
max |
average |
variance |
1 |
Knowledge of working and procedures |
55.0 |
95.0 |
73.3 |
151.9 |
2 |
The ability to determine the working requirements |
4.0 |
94.0 |
70.8 |
330.9 |
3 |
Knowledge of regulations and technical concepts related to work |
51.0 |
91.0 |
73.9 |
138.8 |
4 |
The ability to determine the working procedures and timetable |
50.0 |
94.0 |
74.0 |
98.0 |
5 |
Achieving the required task at the right time |
59.0 |
91.0 |
76.3 |
59.3 |
6 |
Implementation quality and skills followed |
70.0 |
90.0 |
77.1 |
43.3 |
7 |
The ability of audit and review |
70.0 |
90.0 |
77.2 |
52.3 |
8 |
Capacity to develop |
58.0 |
88.0 |
74.3 |
59.1 |
9 |
Optimal utilization of working hours |
59.0 |
88.0 |
77.1 |
55.7 |
10 |
Ability to overcome the difficulties |
50.0 |
89.0 |
72.5 |
132.7 |
11 |
Keeping up to date on new issues |
50.0 |
89.0 |
74.9 |
97.2 |
12 |
Ability to communicate with others effectively |
50.0 |
88.0 |
74.2 |
62.7 |
13 |
Effective participation in meetings |
70.0 |
88.0 |
74.7 |
28.6 |
14 |
Initiative and able to provide alternative solutions in different tasks |
70.0 |
93.0 |
76.7 |
62.6 |
15 |
Ability to train others and transfer the knowledge |
70.0 |
88.0 |
74.2 |
29.2 |
16 |
The ability of discussion and expressing the opinion |
70.0 |
89.0 |
73.8 |
27.7 |
17 |
The ability to estimate the risk |
55.0 |
88.0 |
73.2 |
74.9 |
18 |
Addressing the growing challenges transparently |
58.0 |
90.0 |
72.9 |
107.0 |
19 |
Well-behaved |
60.0 |
90.0 |
76.4 |
69.9 |
20 |
Dependable |
55.0 |
82.0 |
71.3 |
35.8 |
21 |
Accepting the instructions and willing to take action |
53.0 |
90.0 |
74.1 |
99.0 |
22 |
Working skills in a team |
50.0 |
87.0 |
72.3 |
60.7 |
23 |
Preservation of work property |
51.0 |
80.0 |
72.6 |
57.9 |
24 |
Keeping work official secrets |
50.0 |
80.0 |
70.8 |
56.0 |
25 |
Good-looking |
55.0 |
80.0 |
70.8 |
51.4 |
26 |
Relationship with managers |
59.0 |
91.0 |
76.2 |
46.5 |
27 |
Relationship with colleagues |
59.0 |
94.0 |
76.3 |
46.7 |
28 |
Relationship with clients |
53.0 |
89.0 |
73.1 |
93.0 |
output |
Overall |
65.9 |
83.8 |
74.1 |
32.3 |
The statistical method has demonstrated that all of these items are significantly correlated with one another, and the validation test on their relationships has demonstrated that they are highly significant. Using «Linear regression», it was determined that Technology (Artificial Intelligence) Adoption influences Use of artificial intelligence by 62 percent, whereas the Use of artificial intelligence influences «Performance software benefit of Performance Appraisal by 41 percent, and 74 percent to the «Performance aims/obligations» by Technology (Artificial Intelligence) Adoption. However, «Clarity of job description» has a positive impact on «Performance of software benefit of Performance Appraisal 51 percent 69 percent by »Performance aims/objectives of Performance Appraisal. «It has a positive impact on «Performance of software benefit of Performance Appraisal» and a negative impact on «Performance aims/objectives of Performance Appraisal». Genetic Algorithms, Decision Trees, and Neural networks are used in conjunction with the statistical approach due to the success of the statistical approach.
2.7. Performance Evaluation
Performance appraisal is one of the core dimensions in this study, with 11 items, followed by «Performance and Software Benefit» with 6 items, «Performance Aims/Objectives» with 5 items, «Job Description» with 13 items, «Clarity» with 8 items, «Importance» with 5 items, «Utilization of Artificial Intelligence» with 11 items, and «Technology Adoption Factors» with 8 items. The statistical method has demonstrated that all of these items are significantly correlated with one another, and the validation test on their relationships has demonstrated that they are highly significant. A technique known as «Linear regression» has been employed to determine the strength of their impact on predicting the influence of each variable, with the goal of determining the influence of Technology (Artificial Intelligence) Adoption. While the use of artificial intelligence increases the benefit of performance appraisals by 62 percent, it has a negative impact on the «Performance software benefit» of Performance Appraisal by 41 percent and 74 percent on the «Performance aims/objectives», while it increases the «clarity of job description» and the «importance of job description. «However, «Clarity of job description» has a positive impact on «Performance of software benefit of Performance Appraisal 51 percent 69 percent by «Performance aims/objectives of Performance Appraisal». It has a positive impact on «Performance of software benefit of Performance Appraisal» and a negative impact on «Performance aims/objectives of Performance Appraisal». Given the success of the statistical approach, the Genetic Algorithm, Decision Tree, and Neural Network are all used in conjunction with it.
In order to model the performance of the employees, a variety of algorithms have been used, beginning with a linear model such as regression, decision trees, and a Genetic Algorithm optimised linear model, and progressing to a non-linear model such as a neural network. It is necessary to conduct a comparison study in order to determine the validity of each betting model before it can be used in the system to select the best one.
3. Simulation Analysis
MATLAB was used for all analyses. The train and testing sets are stored separately. The regression model was developed using MATLAB’s regress function with 28 inputs and the out-put being employee performance. Other algorithms are required to look for non-linear parameters when using a linear regression model. GA is used to search for the model parameter which is the same structure as the model. To offset and bias in the data, a constant term is added. the search parameters are constricted to [0,3] The GA toolbox’s default setting is «Population size: 200», «Coding: real number», «Selection: Stochastic», «Number of iterations: 1000», «Cross over probability: 80 percent» and «Mutation probability: 5 percent». The same training data is used to generate the decision tree. FitCTree is used to generate the tree. Neural networks are developed using training and testing data. models are developed using MATLAB neural network toolboxes (fitnet). To find the best network structure, various topologies were tested. Single hidden layer with 10 neurons, sigmoid activation function for the hidden layer, and linear activation functions for the output layer give the best performance.
4. Presentation of the Results and Discussion
The GA linear equation fitting is shown in Figure 2 using the training data, while the testing is show using the fitted equation obtained by the GA algorithm as shown in Figure 3. The training and testing model RMS are 0.0363, and 0.2111 respectively. It is noted that the training and testing errors are more balanced in comparison to the linear regression technique. Table 3 lists the variables and the associated parameters.
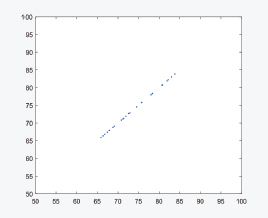
Figure 2. Genetic algorithm linear equation using training data
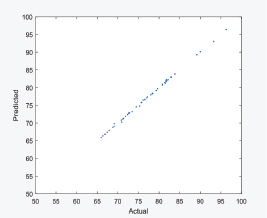
Figure 3. Genetic algorithm linear equation using testing data
Table 3. Genetic algorithm linear equation parameters fitting
Var no. |
Name |
Para. |
1 |
Knowledge of working and procedures |
0.0380 |
2 |
The ability to determine the working requirements |
0.0365 |
3 |
Knowledge of regulations and technical concepts related to work |
0.0220 |
4 |
The ability to determine the working procedures and timetable |
0.0609 |
5 |
Achieving the required task at the right time |
0.0247 |
6 |
Implementation quality and skills followed |
0.0533 |
7 |
The ability of audit and review |
0.0142 |
8 |
Capacity to develop |
0.0303 |
9 |
Optimal utilization of working hours |
0.0523 |
10 |
Ability to overcome the difficulties |
0.0314 |
11 |
Keeping up to date on new issues |
0.0325 |
12 |
Ability to communicate with others effectively |
0.0216 |
13 |
Effective participation in meetings |
0.0617 |
14 |
Initiative and able to provide alternative solutions in different tasks |
0.0357 |
15 |
Ability to train others and transfer the knowledge |
0.0114 |
16 |
The ability of discussion and expressing the opinion |
0.0462 |
17 |
The ability to estimate the risk |
0.0109 |
18 |
Addressing the growing challenges transparently |
0.0398 |
19 |
Well-behaved |
0.0087 |
20 |
Dependable |
0.0469 |
21 |
Accepting the instructions and willing to take action |
0.0715 |
22 |
Working skills in a team |
0.0173 |
23 |
Preservation of work property |
0.0290 |
24 |
Keeping work official secrets |
0.0630 |
25 |
Good-looking |
0.0313 |
26 |
Relationship with managers |
0.0231 |
27 |
Relationship with colleagues |
0.0454 |
28 |
Relationship with clients |
0.0416 |
|
offset |
0.0363 |
RMS: Training: 0.0363, testing: 0.2111 |
||
The finding associated to decision trees reveals that the tree was created and displayed in the manner depicted in Figure 4. One of the disadvantages of using a decision tree is that it is dependent on one of the variables in order to begin at the root of the tree. If such information is not available for a specific employee, or if the employee’s score is low, the final results will be influenced by this. Figure 5 depicts the relative importance of each independent variable in the decision-making procedure. It is demonstrated that the knowledge of the job and the ability to determine the work procedure are the most important factors that differ from the linear model of performance.

Figure 4. Decision tree given by the training data
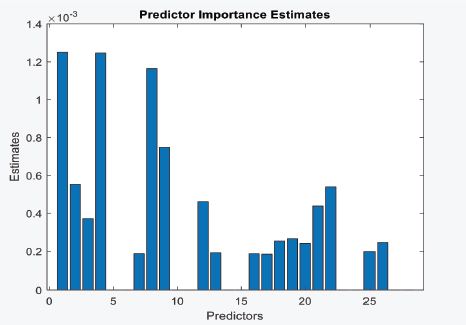
Figure 5. Decision tree Variables Importance
The finding associated with Neural Network based on the fact that the network was trained using the default settings, the training performance of the network which took 784 epochs to reach the best fitting. Figure 6 present the model fitting.
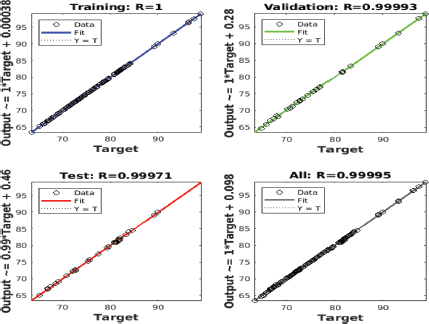
Figure 6. Neural Network Model Predictions
The model fitting (predicted against actual) for the training, validation, and all data) indicated that the training and testing model RMS are 9.8114E-4, and 0.0970 respectively while the coefficient of R2 for the training is perfect at 1. This is much better accuracy in comparison to other models. In particular, the testing accuracy is the least in comparison the GA linear equation. In order to evaluate the advantages and disadvantages of the various algorithms that have been used to create an artificial intelligence model for evaluating the performance of employees, a comparison table has been created. The key characteristics of each algorithm, as well as its accuracy, are depicted in Table 4. In terms of computing, ANNs are also more sophisticated than standard methods. Data normalisation and scaling are required by ANN. Low accuracy is sometimes caused by missing values in the data. Biologically inspired computational networks are referred to as ANNs. An artificial neural network (ANN) was created to mimic how the human brain analyses and processes information.
Table 4. Comparison of the four algorithms
Artificial Neural Network (ANN) |
Genetic Algorithm (GA) |
Decision Tree (DT) |
Linear Regression (LR) |
Train RMS = 9.8114E-4 Test RMS = 0.0970 |
Train RMS=0.0363 Test RMS = 0.2111 |
Train RMS=4.1282e-04 |
Train RMS =2.8285E-14 Test RMS = 0.3211 |
GA outperforms linear regression in terms of processing power. GA necessitates data standardisation and scaling. Low accuracy is sometimes caused by missing values in the data. GA uses a natural selection approach that replicates biological evolution to tackle both confined and unconstrained optimization problems. Because of the complexity and time required, DT training is relatively costly. Data normalisation and scaling are not required while using DT. In addition, missing values in the data have no significant impact on the decision tree-building process. DT is a popular data mining method for creating classification systems with various variables or generating prediction algorithms for a target variable. When compared to other machine learning techniques, LR has a significantly lesser processing power. LR almost perfectly fits linearly separable datasets and is frequently used to determine the nature of the relationship between variables. By fitting a linear equation to observed data, LR seeks to model the relationship between two variables. One variable is regarded as an explanatory variable, while the other is regarded as a dependent variable.
Due to the fact that the nonlinear modelling technique and other advantages not accessible in other algorithms, the artificial neural network was found to have the best outcomes out of the four generated models used in the performance rating software.
5. Conclusion
This paper identifies that dedicated HRMS, specifically HRMS used for human resource-related functions, govern day-to-day HR management operations. There will typically be an entire department’s tasks across the board in each company which must be flawless. That is why the study examined machine learning approach toward evaluating role-based tasks associated with organizational unit. To determine which algorithms produce better results on the programme, this paper has examined the algorithms (Genetic Algorithm, Decision Tree, and Linear Regression, as well as Neural Network) that have been tested on the programme. The ease with which individual roles can be assigned to users within an organisation, as well as the importance of ensuring that the tasks are carried out effectively, have been discussed throughout this paper. A Neural Network composed of classification and regression tree links was used to evaluate the effectiveness of role-based tasks associated with an organization unit as a result of the findings of this study. In order to obtain comprehensive information about their employees’ performance levels, as well as their capabilities, skills, and the tasks they perform and how they perform them, a Human Resource Management System (HRMS) was designed and developed for them. In order to evaluate machine learning, data sets were extracted from the system’s evaluation and used for machine learning evaluation. The neural network algorithms have been selected because they are the most effective and advantageous for the program’s needs. It was revealed that the neural network yielded the greatest results out of the four developed models that were employed in the performance rating software, this was owing to the nonlinear modelling technique used, as well as additional advantages that were not available when using other techniques. Results of the study can be used to streamline the assignment of specific roles to users within an organisation and to ensure that duties are carried out efficiently.
In contrast to the current study, which used Ensembles integrating four learning algorithms to build a better of them and found the best, a future study should use the best of any of the constituent learning algorithms individually to find the best results. In the current study, it was demonstrated that while Bootstrap aggregation was used because of its consistent allocation of equal weight, future studies should make use of Boosting because it involves incrementally building the training instances and also because it is a technique in which a model selection algorithm is used to select the best model for each problem, as demonstrated in the current study, Boosting is a technique in which a model selection algorithm is used to select the best model for each problem, as demonstrated in the current study. It is also possible to employ the technique of stacking, which is an approach to combining the predictions of several different learning algorithms. Even though the focus of this study is on the four algorithms that indicate their performance, along with their advantages and disadvantages, as well as the reasoning behind their selection for use in the development of the performance appraisal system, future research should explore more predictive analytic algorithms to further explore the situation. However, the fundamental factors that will influence the success of AI adoption in human resource management are not covered in the scope of the studies provided above. Although AI’s promise in HRM and the ease with which it appears to increase HRM performance over time are important factors, future studies will look at ways to improve AI in HRM.
References
Abdeldayem, M. M., and Aldulaimi, S. H. (2020). Trends and opportunities of artificial intelligence in human resource management: Aspirations for public sector in Bahrain. International Journal of Scientific and Technology Research, 9(1), 3867–3871.
Bhardwaj, G., Singh, S. V., and Kumar, V. (2020, January). An empirical study of artificial intelligence and its impact on human resource functions. In 2020 International Conference on Computation, Automation and Knowledge Management (ICCAKM) (pp. 47–51). IEEE.
Bilgic, E. (2020). Human Resources Information Systems: A Recent Literature Survey. Contemporary Global Issues in Human Resource Management.
Boxall, P. (2013). Mutuality in the management of human resources: assessing the quality of alignment in employment relationships. Human resource management journal, 23(1), 3–17.
Breiman, L. (1996). Bagging predictors. Machine learning, 24(2), 123–140.
Bühlmann, P. (2012). Bagging, boosting and ensemble methods. In Handbook of computational statistics (pp. 985–1022). Springer, Berlin, Heidelberg.
Dou, J., Yunus, A. P., Bui, D. T., Merghadi, A., Sahana, M., Zhu, M., Chen, C.W., Han, Z. and Pham, B.T., (2020). Improved landslide assessment using support vector machine with bagging, boosting, and stacking ensemble machine learning framework in a mountainous watershed, Japan. Landslides, 17(3), 641–658.
Duan, Q., Ajami, N. K., Gao, X., and Sorooshian, S. (2007). Multi-model ensemble hydrologic prediction using Bayesian model averaging. Advances in Water Resources, 30(5), 1371–1386.
Folino, F., Folino, G., Guarascio, M., Pisani, F. S., and Pontieri, L. (2021). On learning effective ensembles of deep neural networks for intrusion detection. Information Fusion, 72, 48–69.
Gong, M., Xie, Y., Pan, K., Feng, K., and Qin, A. K. (2020). A survey on differentially private machine learning. IEEE Computational Intelligence Magazine, 15(2), 49–64.
Gupta, V., Choudhary, K., Tavazza, F., Campbell, C., Liao, W. K., Choudhary, A., and Agrawal, A. (2021). Cross-property deep transfer learning framework for enhanced predictive analytics on small materials data. Nature communications, 12(1), 1–10.
Jääskeläinen, A., SiUanpää, V., Helander, N., Leskelä, R. L., Haavisto, I., Laasonen, V., and Torkki, P. (2020). Designing a maturity model for analyzing information and knowledge management in the public sector. VINE Journal of Information and Knowledge Management Systems.
Jawabreh, O., Jahmani, A., Khaleefah, Q., Alshatnawi, E., and Abdelrazaqe, H. (2020). Customer Expectation in Five Star Hotels in Aqaba Special Economic Zone Authority (ASEZA). International Journal of Innovation, Creativity and Change, 11(4) 417–438.
Karlaftis, M. G., and Vlahogianni, E. I. (2011). Statistical methods versus neural networks in transportation research: Differences, similarities and some insights. Transportation Research Part C: Emerging Technologies, 19(3), 387–399.
Kolbjørnsrud, V., Amico, R., and Thomas, R. J. (2016). How Artificial Intelligence Will Redefine Management. Harvard Business Review. Retrieved from https://hbr.org/2016/11/how-artificial-intelligence-will-redefine-management.
Laudon, K. C., and Laudon, J. P. (2015). Management information systems (p. 143). Upper Saddle River: Pearson
Lim, S., Wang, T. K., and Lee, S. Y. (2017). Shedding new light on strategic human resource management: The impact of human resource management practices and human resources on the perception of federal agency mission accomplishment. Public Personnel Management, 46(2), 91–117.
Maier, C., Laumer, S., Eckhardt, A., and Weitzel, T. (2013). Analyzing the impact of HRIS implementations on HR personnel’s job satisfaction and turnover intention. The Journal of Strategic Information Systems, 22(3), 193–207.
Margherita, A., Sharifi, H., and Caforio, A. (2021). A conceptual framework of strategy, action and performance dimensions of organisational agility development. Technology Analysis & Strategic Management, 33(7), 829–842.
Melville, N. P. (2010). Information systems innovation for environmental sustainability. MIS quarterly, 34(1), 1–21.
Montgomery, D. C., Peck, E. A., and Vining, G. G. (2021). Introduction to linear regression analysis. John Wiley & Sons.
Moretti, F., Pizzuti, S., Panzieri, S., and Annunziato, M. (2015). Urban traffic flow forecasting through statistical and neural network bagging ensemble hybrid modeling. Neurocomputing, 167, 3–7.
Qamar, Y., Agrawal, R. K., Samad, T. A., and Jabbour, C. J. C. (2021). When technology meets people: the interplay of artificial intelligence and human resource management. Journal of Enterprise Information Management.
Saiz-Rubio, V., and Rovira-Más, F. (2020). From smart farming towards agriculture 5.0: A review on crop data management. Agronomy, 10(2), 207.
Schultze, U., and Leidner, D. E. (2002). Studying knowledge management in information systems research: discourses and theoretical assumptions. MIS quarterly, 26(3), 213–242.
Seni, G., and Elder, J. F. (2010). Ensemble methods in data mining: improving accuracy through combining predictions. Synthesis lectures on data mining and knowledge discovery, 2(1), 1–126.
Sony, M., and Naik, S. (2020). Industry 4.0 integration with socio-technical systems theory: A systematic review and proposed theoretical model. Technology in Society, 61, 101248.
Spooner, A., Chen, E., Sowmya, A., Sachdev, P., Kochan, N. A., Trollor, J., and Brodaty, H. (2020). A comparison of machine learning methods for survival analysis of high-dimensional clinical data for dementia prediction. Scientific reports, 10(1), 1–10.
Tambe, P., Cappelli, P., and Yakubovich, V. (2019). Artificial intelligence in human resources management: Challenges and a path forward. California Management Review, 61(4), 15–42.
Trejos, J., Villalobos-Arias, M. A., and Espinoza, J. L. (2016). Variable selection in multiple linear regression using a genetic algorithm. In Handbook of research on modern optimization algorithms and applications in engineering and economics (pp. 133–159). IGI Global.
Ullah, Z., Ahmad, N., Scholz, M., Ahmed, B., Ahmad, I., and Usman, M. (2021). Perceived accuracy of electronic performance appraisal systems: The case of a non-for-profit organization from an emerging economy. Sustainability, 13(4), 2109.
Usman, A. G., Işik, S., and Abba, S. I. (2020). A novel multi-model data-driven ensemble technique for the prediction of retention factor in HPLC method development. Chromatographia, 83, 933–945.
Vu, T. M., Probst, C., Nielsen, A., Bai, H., Buckley, C., Meier, P. S., and Purshouse, R. C. (2020). A software architecture for mechanism-based social systems modelling in agent-based simulation models. Journal of artificial societies and social simulation: JASSS, 23(3).
Wheeler, A. R., and Buckley, M. R. (2021). The Current State of HRM with Automation, Artificial Intelligence, and Machine Learning. In HR without People? Emerald Publishing Limited.
Yariyan, P., Janizadeh, S., Van Phong, T., Nguyen, H. D., Costache, R., Van Le, H., and Tiefenbacher, J. P. (2020). Improvement of best first decision trees using bagging and dagging ensembles for flood probability mapping. Water Resources Management, 34(9), 3037–3053.
Zhang, J., Liu, X., and Li, X. B. (2020). Predictive analytics with strategically missing data. INFORMS Journal on Computing, 32(4), 1143–1156.